首先说一下本人编程毫无基础小白一枚 ,看了网上很多教程哎都是看的一知半解,最后只会了一种最简单的正则提取。 过程我会讲解的比较详细,作为小白的我当然明白小白的苦,源码一堆看不懂也没用。
import urllib.request #打开模块 import re #模拟一个浏览器代理 headers=("User-Agent","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36 SE 2.X MetaSr 1.0") opener=urllib.request.build_opener() opener.addhaders=[headers] #安装为全局匹配 urllib.request.install_opener(opener) 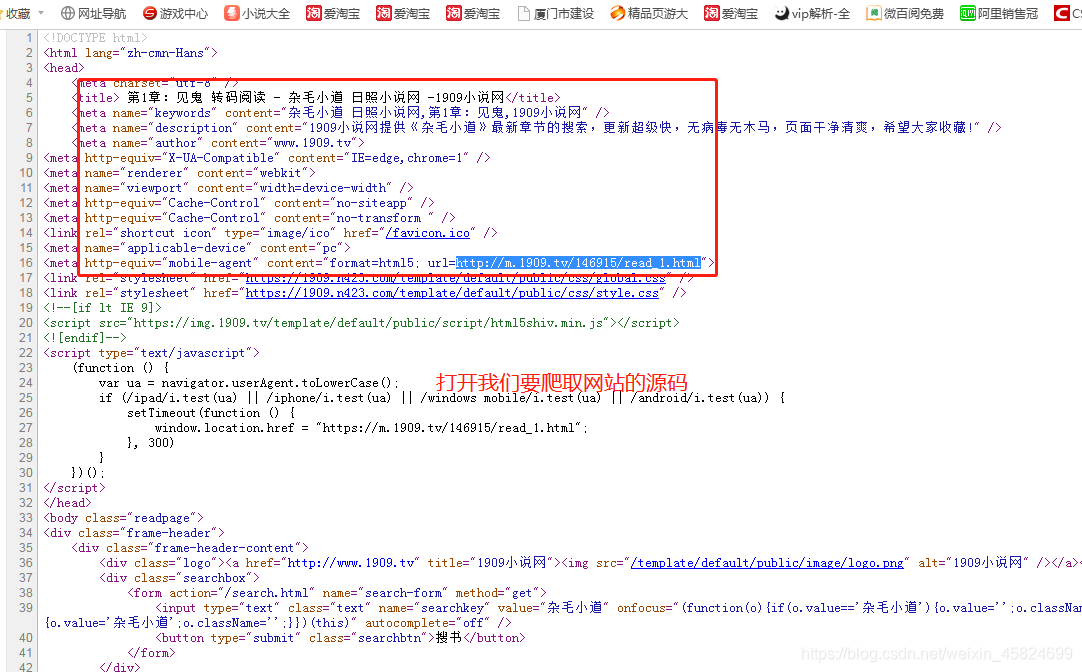 for i in range(0,372): while True: #这里做了一个判断循环 就是出错了还会在出错的那个位置继续爬直到爬到为止 try: #异常处理 sss=('http://m.1909.tv/146915/read_'+str(i+1)+'.html') #这里呢我发现每个章节的最后一个页码是有规律的所以直接搞个循环就OK sss1=('http://m.1909.tv/146915/read_'+str(i+1)+'_2.html') #因为一章分为2页 我又想不到其它方法只能这样搞了 哈哈 data=urllib.request.urlopen(sss).read().decode("UTF-8","ignore") data1=urllib.request.urlopen(sss1).read().decode("UTF-8","ignore") 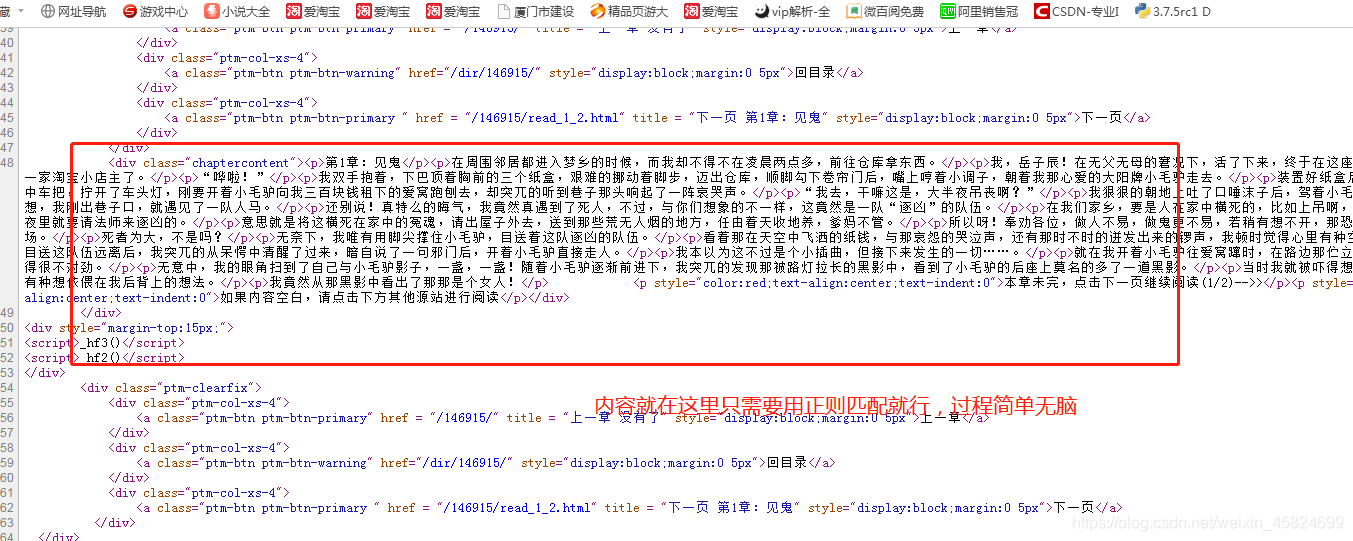 pat='<p>.*?</p><p>.*?</p>' #这个就是匹配正文内容了 ,哎看起来肯定是不怎么好用,但是能用 lis=re.compile(pat).findall(data)#这个就是查找网页内容其实就是字面意思。。。。 lis1=re.compile(pat).findall(data1) sss1=lis,lis1 print(sss1) print('---------------') except Exception as err: continue #print("出现异常") break fh=open("C:\\Users\\Administrator\\Desktop\\杂毛小道.txt","a+",encoding='utf8')#这里能不能写入文件还是个问题。。。。 fh.write(str(sss1)+'\n') fh.close() 总结 就是能用 但是不好用 O(∩_∩)O哈哈~